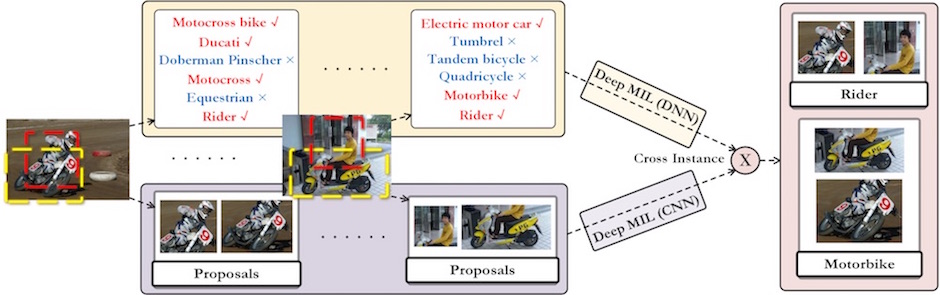
Figure 1: An overview of our Deep Multiple Instance Learning (DMIL) framework and the dual multiple instance assumptions
Abstract
The recent development in learning deep representations has demonstrated its wide applications in traditional vision tasks like classification and detection. However, there has been little investigation on how we could build up a deep learning framework in a weakly supervised setting. In this paper, we attempt to model deep learning in a weakly supervised learning (multiple instance learning) framework. In our setting, each image follows a dual multi-instance assumption, where its object proposals and possible text annotations can be regarded as two instance sets. We thus design effective systems to exploit the MIL property with deep learning strategies from the two ends; we also try to jointly learn the relationship between object and annotation proposals. We conduct extensive experiments and prove that our weakly supervised deep learning framework not only achieves convincing performance in vision tasks including classification and image annotation, but also extracts reasonable region-keyword pairs with little supervision, on both widely used benchmarks like PASCAL VOC and MIT Indoor Scene 67, and also a dataset for image- and patch-level annotations.