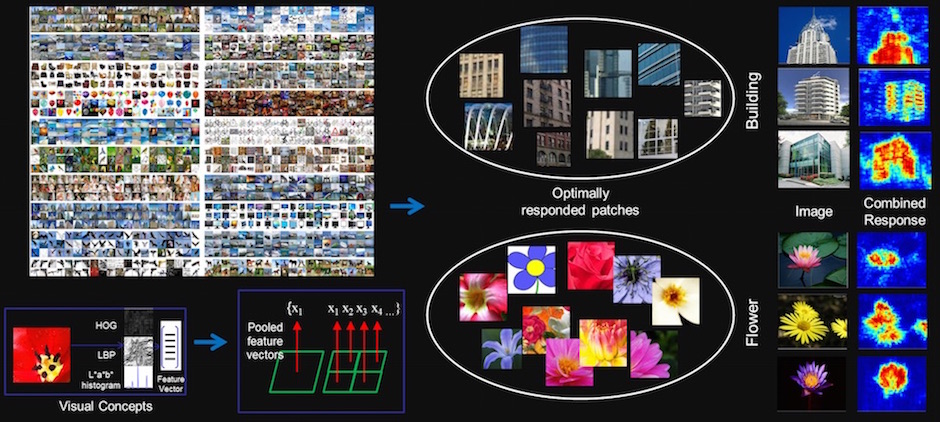
Figure 1: An overview of our framework for harvesting mid-level visual concepts from large-scale Internet images
Abstract
Obtaining effective mid-level representations has become an increasingly important task in computer vision. We propose a fully automatic algorithm which harvests visual concepts from a large number of Internet images (more than a quarter of a million) using text-based queries. Existing approaches to visual concept learning from Internet images either rely on strong supervision with detailed manual annotations or learn image-level classifiers only. Here, we take the advantage of having massive well- organized Google and Bing image data; visual concepts (around 14,000) are automatically exploited from images using word-based queries. Using the learned visual concepts, we show state-of-the-art performances on a variety of benchmark datasets, which demonstrate the effectiveness of the learned mid-level representations: being able to generalize well to general natural images. Our method shows significant improvement over the competing systems in image classification, including those with strong supervision.